Creating a Simple RAG in Python with AzureOpenAI and LlamaIndex
/ 2 min read
During a recent stream, I explored the process of ingesting a PDF using LlamaIndex and AzureOpenAI. This blog post will guide you through the steps to accomplish this task.
The objective was straightforward: answer questions based on information contained in PDF files stored in a folder. Here’s the process we’ll follow:
- Embed the PDF data: Convert PDFs into a format comprehensible for AI
- Initialise AzureOpenAI and provide it with the embedded data
- Ask a question and analyse the response
While the LlamaIndex documentation provides an excellent guide, I’ve included some visual aids to enhance clarity.
Setting Up the Environment
First, let’s install the necessary packages:
pip install python-dotenv llama-index llama-index-llms-azure-openai llama-index-embeddings-azure-openaiNote that AzureOpenAI is not included in the llama-index package and must be installed separately.
Configuring AzureOpenAI
Navigate to Azure AI Studio and deploy your chosen model.
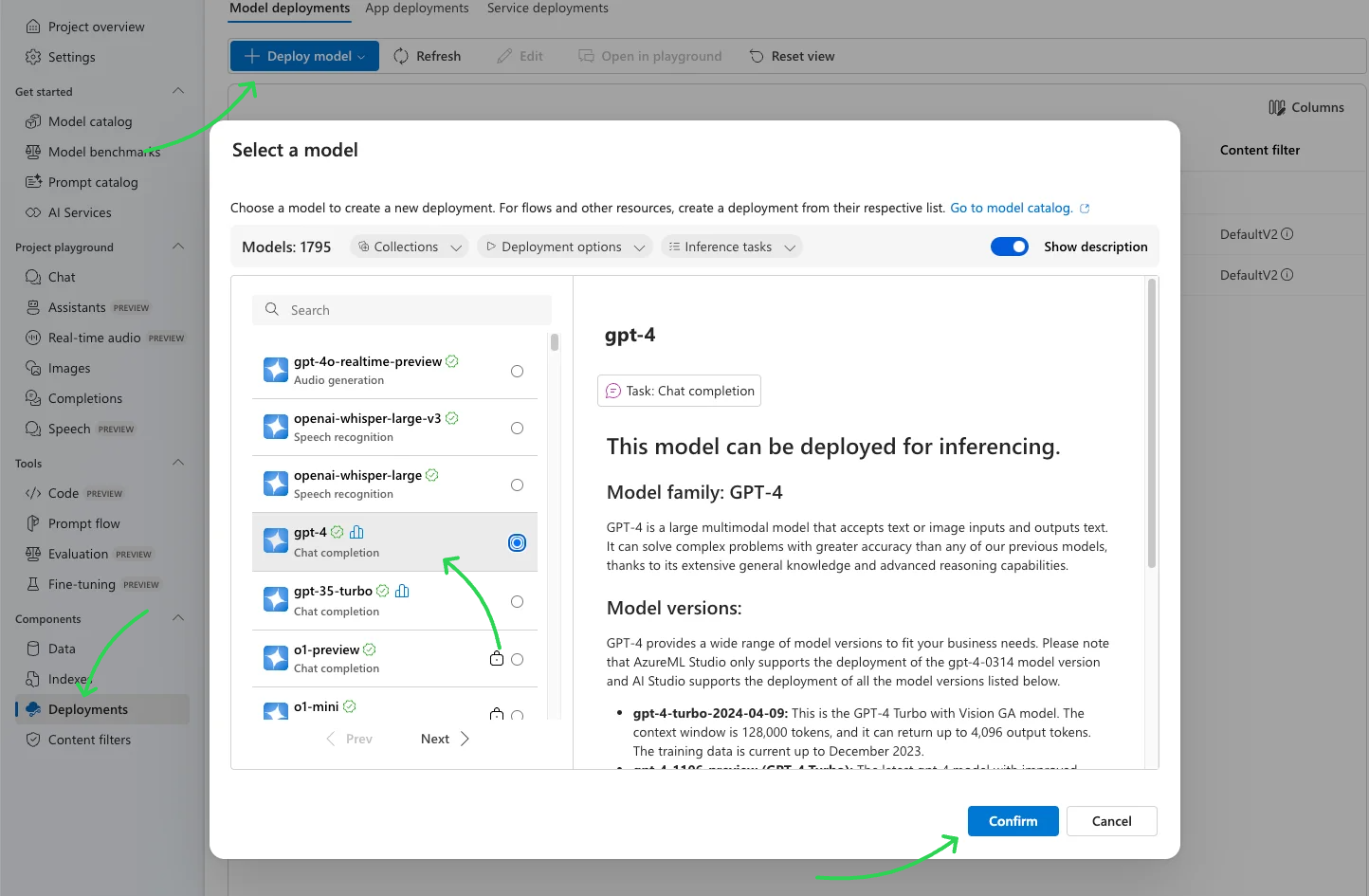
Once deployed, configure LlamaIndex to use it with the following settings:
Settings.llm = AzureOpenAI( engine="gpt-4o-mini", api_key=os.environ.get('AZURE_OPENAI_API_KEY'), azure_endpoint=os.environ.get('AZURE_OPENAI_ENDPOINT'), api_version="2024-05-01-preview",)BUT.
Azure openAI resources unfortunately differ from standard openAI resources as you can’t generate embeddings unless you use an embedding model.
This means that we need a separate embedding model for generating embeddings. Let’s do that.
Deploy an embedding model that starts with text-embedding-*, since in this case we’re working exclusively with text.
Configure LlamaIndex to use the embedding model:
Settings.embed_model = AzureOpenAIEmbedding( model="text-embedding-3-small", deployment_name="text-embedding-3-small", api_key=os.environ.get('AZURE_OPENAI_API_KEY'), azure_endpoint=os.environ.get('AZURE_OPENAI_EMBEDDING_ENDPOINT'), api_version='2023-05-15',)Implementing the RAG System
With the setup complete, let’s load PDFs into the data folder and query the model:
def main(): documents = SimpleDirectoryReader("data").load_data() index = VectorStoreIndex.from_documents(documents) query_engine = index.as_query_engine() response = query_engine.query("Can we advertise online gambling to under 18 year olds?") print(response)To run the script in our virtual environment:
python3 -m venv .venvsource .venv/bin/activatepip install -r requirements.txtpython ./src/main.pyAnd we get a response of
No, advertising online gambling to under 18 year olds is not permitted. Marketing communications must not exploit the vulnerabilities of this age group, and any advertisements that feature under-18s or are directed at them are likely to be considered irresponsible and in breach of established rules.Future Improvements
We can make it better by embedding the data once and storing it in a database like Azure CosmosDB, which is a MongoDB at its core. This means we get rid of repetitive embedding overhead every time we run the script, allowing the LLM to access pre-embedded data directly from the database. I’ll cover this in my future posts.
And here is the repo with this and any future code.
Next: Creating a Simple RAG in Python with AzureOpenAI and LlamaIndex. Part 2.